Estructuras de datos
Las estructuras de datos nos permite almacenar y manipular información compleja compuesta de datos básicos (números, booleanos, caracteres, etc.) y otras estructuras de datos en nuestros programas y algoritmos.
Arreglos
Seguramente ya conoces los arreglos pero es importante saber que existen dos tipos de arreglos: estáticos y dinámicos.
Los arreglos estáticos tienen una longitud fija mientras que los dinámicos tienen una longitud variable. En C, C++ y Java, entre otros, los arreglos son estáticos mientras que en JavaScript, Ruby y Python, entre otros, son dinámicos.
Los arreglos dinámicos son mucho más flexibles pero pueden llegar a ser lentos u ocupar más espacio en memoria (recuerda que JavaScript y Ruby están escritos en lenguajes de más bajo nivel como C o C++ que no soportan arreglos dinámicos).
Este enlace explica cómo están implementados los arreglos de JavaScript.
Diccionarios
Los diccionarios están compuestos de llaves y valores. La principal característica de un diccionario es que la búsqueda de un elemento por llave es constante O(1).
La mayoría de lenguajes incluyen diccionarios. En Ruby se llaman hashes, en JavaScript objetos y en Python diccionarios.
Listas encadenadas
Las listas encadenadas son similares a los arreglos, en el sentido que son una lista de elementos, pero la implementación es diferente.
Una lista encadenada está compuesta de nodos. Cada nodo tiene un valor y una referencia al siguiente nodo como se muestra en la siguiente imagen:

La ventaja principal de una lista encadenada (sobre un arreglo) es que insertar elementos en la mitad de la lista es muy fácil (sólo se deben cambiar las referencias de los nodos). Sin embargo, la desventaja es que no se puede acceder a una posición aleatoria (toca recorrer la lista hasta llegar a la posición).
La lista también puede estar doblemente encadenada, es decir, cada nodo tiene una referencia al siguiente y al anterior.
Las operaciones principales de una lista encadenada son:
- Insertar un valor en una posición (por defecto al final).
- Obtener un valor por posición.
- Recorrer las posiciones.
- Eliminar una posición.
const list = new LinkedList();
list.add('a');
list.add('b');
list.add('d');
list.addAt(2, 'c');
list.valueAt(0); // 'a'
list.forEach((val, i) => {
console.log(`Value at position ${i}: ${val}`);
});
list.removeAt(0);
La operación add es O(n) aunque se puede mantener una referencia interna al último nodo de la lista y se convertiría en O(1).
Las operaciones addAt, valueAt y removeAt son O(n) porque toca recorrer la lista hasta llegar a la posición deseada.
En la vida real las listas encadenadas no son muy comunes (los arreglos funcionan bien en la mayoría de los casos) pero igual es importante saber que existen y es un buen ejercicio hacer la implementación.
Colas (queues)
Una cola es una estructura que permite agregar elementos al final de la lista y obtener el primero (como una fila de pago en un supermercado). A esto se le conoce como PEPS (primero en entrar, primero en salir).
Las operaciones principales de una cola son:
- Agregar un valor.
- Obtener el primer valor.
- Obtener el tamaño.
Las colas se usan en programación principalmente para almacenar información que va a ser procesada en el futuro.
Las colas se pueden implementar sobre un arreglo limitando las operaciones para que se comporte como una cola (p.e. no se debe poder obtener un elemento por posición ni insertar en cualquier posición).
## Pilas (stacks)
Una pila es una estructua que permite agregar elementos al inicio de una lista y obtener el primero (como una pila de libros en la que solo puedes tomar el libro de la parte superior, y en la que solo puedes ubicar libros encima de los demás). A esto se le conoce como UEPS (último en entrar, primero en salir).
Las operaciones principales de una pila son:
- Agregar un valor.
- Obtener el último valor agregado.
- Obtener el tamaño.
Las pilas se pueden implementar utilizando un arreglo y limitando las operaciones para que se comporte como una pila (p.e. no se debe poder obtener un elemento por posición ni insertar en cualquier posición).
Árboles
Los árboles están compuestos de nodos como las listas encadenadas. Sin embargo, un árbol tiene un nodo raíz con referencia a cero o más nodos hijos. Estos nodos, a su vez, tienen referencias a otros nodos hijos, y así sucesivamente.
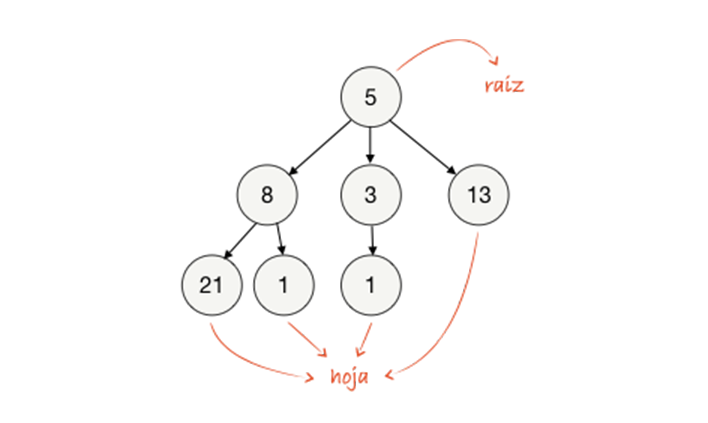
A los nodos que no tienen hijos se le conoce como un nodo hoja.
Un árbol en el que cada nodo puede tener máximo dos hijos se le conoce como un árbol binario.
Un árbol puede ser ordenado o desordenado.
En la vida real los árboles se utilizan para representar jerarquías (p.e. las posiciones en una empresa, los elementos en HTML, etc.) y optimizar búsquedas.
La forma más fácil de implementar un árbol es utilizando nodos interconectados, similar a como se implementan las listas encadenadas. La diferencia es que la lista encadenada sólo tiene una referencia a otro nodo mientras que los árboles pueden tener varias referencias a otros nodos.
Las operaciones más importantes de un árbol son:
- Insertar un nodo (dependiendo del tipo de árbol la ubicación puede ser asignada automática o manualmente).
- Remover un nodo
- Recorrer el árbol
Existen dos formas de recorrer un árbol. La primera es empezar por la raíz y recorrer la rama izquierda. Una vez se ha recorrido toda esa rama se realiza el mismo proceso con las demás ramas que se desprenden de la raíz. A este proceso se le conoce como búsqueda por profunidad, en inglés Depth-First Search (DFS).
La otra forma es ir imprimiendo nivel por nivel. Se inicia por la raíz, después se imprimen todos los hijos de la raíz. Después se imprimen todos los nietos y así sucesivamente (por niveles). A este proceso se le conoce como búsqueda en anchura, en inglés Breadth-First Search (BFS).
Ejercicio
Implementar un árbol binario que vamos a utilizar de la siguiente forma:
const tree = new BinaryTree();
tree.add(4);
tree.add(2);
tree.add(7);
tree.add(1);
tree.add(3);
El árbol debe queda de la siguiente forma:
4
/ \
2 7
/ \
1 3
Adicionalmente al método add intenta implementar el método traverseDFS (recorrido de profundidad) y traverseBFS (recorrido de anchura) que reciben una función:
tree.traverseDFS(function(e) { console.log(e); });
// 4
// 2
// 1
// 3
// 7
tree.traverseBFS(function(e) { console.log(e); });
// 4
// 2
// 7
// 1
// 3
Grafos
Los grafos son nodos interconectados entre sí a través de conexiones.

Nota: A los nodos se les conoce como vértices y a las conexiones como aristas (en Inglés edges).
El grafo de la imagen está direccionado, es decir, cada conexión va en un solo sentido o dirección. Un grafo también puede ser doblemente direccionado (las conexiones van en ambos sentidos) como se muestra en la siguiente imagen:
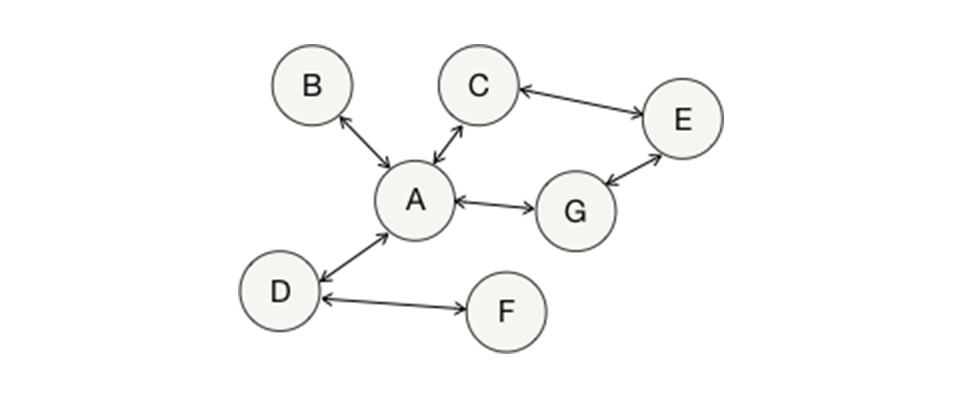
Las conexiones pueden tener un peso (un valor) como se muestra en la siguiente imagen:

Los gráfos pueden contener ciclos o ser acíclico (sin ciclos).
Existen muchas formas de implementar los grafos: lista de adyacencia, matriz de adyacencia o como una lista de nodos con referencia a otros nodos (similar a como se implementaría una lista encadenada o un árbol). La implementación depende en gran parte del problema que se quiere solucionar.
Nota: Las listas encadenadas y los árboles son grafos con ciertas restricciones (p.e. una lista encadenada es un grafo acíclico que tiene una cabeza y en donde cada nodo solo puede estar conectado a máximo otro nodo).
Listas de adyacencia
Se utiliza un diccionario en donde la llave representa el nodo y el valor es un arreglo que hace referencia a los otros nodos a los que está conectado.
const graph = {
"A": ["C", "G"],
"B": ["A"],
"C": ["E"],
"D": ["A", "F"],
"E": [],
"F": [],
"G": ["E"]
}
Si las conexiones tienen un peso se puede agregar esta información en la lista de adyacencia, por ejemplo:
const graph = {
"A": [{ n: "C", p: 6 }, { n: "G", 3 }],
...
}
Matrices de adyacencia
Se utiliza una matriz (un arreglo de arreglos) para representar las relaciones en donde cada fila y columna representa un nodo. Las intersecciones representan las conexiones, se utiliza un 0 si no hay conexión y un 1 si la hay.
const graph: [
[-1, 0, 1, 0, 0, 1, 0],
[1, -1, 0, 0, 0, 0, 0],
[0, 0, -1, 0, 1, 0, 0],
[1, 0, 0, -1, 0, 1, 0],
[0, 0, 0, 0, -1, 0, 0],
[0, 0, 0, 0, 1, -1, 0],
[0, 0, 0, 0, 0, 0, -1]
];
Si las conexiones tienen peso se puede utilizar el peso en vez de 1 para representar las conexiones.
Nodos interconectados
Se utiliza una estructura de datos adicional que tiene un nombre (o un valor) y un arreglo de referencia a otros nodos:
function Node(name, refs) {
this.name = name;
this.refs = refs;
}
const a = new Node("A");
const b = new Node("B");
const c = new Node("C");
const d = new Node("D");
const e = new Node("E");
const f = new Node("F");
const g = new Node("F");
a.refs.push(c, g);
b.refs.push(a);
c.refs.push(e);
d.refs.push(a, f);
g.refs.push(e);
Conjuntos (sets)
Un conjunto es una lista de elementos que no permite valores duplicados. La mayoría de lenguajes de programación incluyen esta estructura de datos (p.e. JavaScript tiene el objeto Set).
Las operaciones principales de un conjunto son:
- Agregar un valor
- Obtener el tamaño del conjunto.
- Verificar si existe un valor.
- Eliminar un valor.
En JavaScript podemos utilizar Set de la siguiente forma.
const mySet = new Set();
mySet.add(1); // Set [ 1 ]
mySet.add(5); // Set [ 1, 5 ]
mySet.add(5); // Set [ 1, 5 ]
mySet.size; // 2
mySet.has(1); // true
mySet.delete(5); // removes 5 from the set